Monat: August 2014
-
Schulentwicklungsprogramm und Erziehungspartnerschaft
(12 Kommentare.) Mit der letzten Änderung des BayEUG vom Sommer 2013 muss jede Schule so etwas haben. Nämlich einmal das hier: Art. 2, Abs. 4, Satz 4: In einem Schulentwicklungsprogramm bündelt die Schule die kurz- und mittelfristigen Entwicklungsziele und Maßnahmen der Schulgemeinschaft unter Berücksichtigung der Zielvereinbarungen gemäß Art. 111 Abs. 1 Satz 1 Nr. 2…
-

Chicken Tikka Masala
(4 Kommentare.) Curries koche ich sporadisch seit über zwanzig Jahren. Ich habe diverse Rezepte, diverse Kochbücher ausprobiert; nie systematisch oder wirklich ernsthaft, aber doch in ordentlichem Unfang. Die Ergebnisse waren mäßig bis gut, teilweise auch sehr lecker – aber nie kamen sie an das heran, was ich aus England kannte. (Anders als die Rezepte für…
-

Derberer Humor
Was ein roast ist, weiß ich seit 1982, als ich das Comic-Heft Fantastic Four Roast #1 las: (Titelbild: Fred Hembeck und Terry Austin) Das ist eine festliche Veranstaltung zu Ehren eines Gastes, der während dieser Veranstaltung von Gastrednern durch den Kakao gezogen wird. Berühmt sind die Roasts des Friars Club in New York. Zum ersten…
-
Lucy
Im Kino gewesen, Lucy gesehen, von Luc Besson, mit Scarlett Johansson. Mancherorts wird der ja als Superheldenfilm verkauft oder in eine Reihe von Superheldenfilmen gestellt. Dabei kommt der Film für mich aus einer ganz anderen Ecken: Dem Monsterfilm der 1950er Jahre oder dem Verrückten Wissenschaftler der frühen 1960er. Darum geht es in Lucy: Unfreiwillige Drogenkurierin…
-
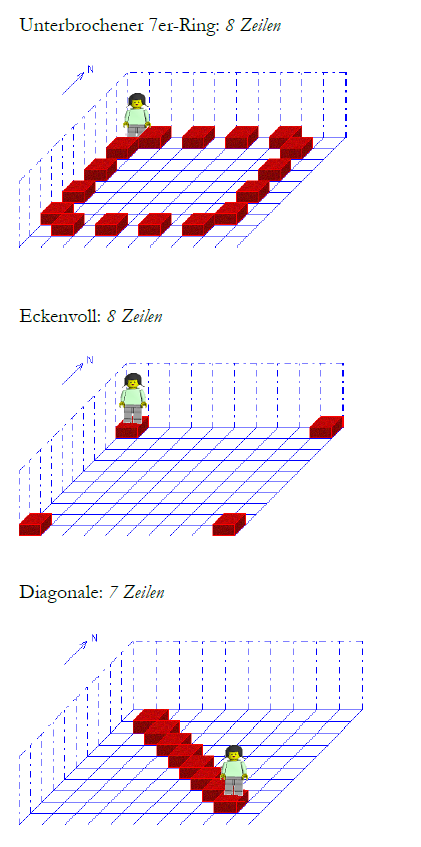
Schleifchenmachen
(2 Kommentare.) In der 7. Klasse lernen die Schüler am bayerischen Gymnasium Algorithmik „mit einem Programmiersystem, mit dem sie die Algorithmen intuitiv umsetzen können und bei dem die Einzelschritte des Ablaufs altersgemäß visualisiert werden“ (Lehrplan). Das heißt in der Regel: Robot Karol, das virtuelle Legomännchen. Es kann Ziegelsteine vor sich ablegen und aufnehmen, kann sich…
-
Verschlüsselung auf Zeit
(5 Kommentare.) Vor ein paar Wochen stellte Klaus Schmeh in Klausis Krypto Kolumne ein Time-Lock-Verschlüsselungsverfahren vor. Um das Prinzip richtig zu begreifen, habe ich das alles nachprogrammiert, und wenn ich mir so viel Mühe mache, dann soll auch ein Blogeintrag dabei herauskommen. Ich bin kein Mathematiker oder Kryptologe und es ist nicht unwahrscheinlich, dass ich…
-

Krähe
(3 Kommentare.) Im Baum vor meinem Fenster wohnt seit wenigen Wochen eine verletzte Krähe. Vielleicht ist sie unter ein Auto gekommen, vielleicht ist ein Flügel gebrochen, jedenfalls kann sie nicht mehr fliegen. Ab und zu lege ich ihr ein paar Erdnüsse hin, in der Schale. Dann gleitet sie vom Baum, isst die Nüsse, dreht vielleicht…
-

Fakten machen (Mythen in Bildung und anderswo)
(18 Kommentare.) It ain’t what a man don’t know that makes him a fool, but what he does know that ain’t so. Wenn es nur so einfach wäre.Mir ist in den letzten Wochen an verschiedenen Stellen aufgefallen, dass es in Ordnung zu sein scheint, Dinge zu wissen, die nicht stimmen. 1. Die Jugend von heute…