Beispiel 7: Autorennspiel
Hier soll die KI lernen, ein Auto eine Strecke entlang zu fahren:

Ich habe die Bedingungen sehr weit reduziert:
- Die befahrbare Strecke ist die Fläche innerhalb des grünen Bereichs; letzterer ist der Rasen und kann nicht befahren werden. Wenn man den Rasen befährt, fängt man wieder an der Startlinie an.
- Das Auto kann vorwärts fahren oder sich nach links drehen und fahren oder nach rechts drehen und fahren. Es gibt keine Beschleunigung.
- Es gibt auch keine anderen Fahrzeuge; das könnte man alles einbauen, wenn die ganz simple Version funktioniert.
- Das Auto startet an der Startlinie; Ziel ist, die Startlinie wieder zu erreichen, und zwar nach einer vollen Runde.
Das KI-System ist genau das gleiche wie bisher. Wieder gibt es zwei Fragen, und nur die müssen programmiert werden, neben Programmierarbeit, bei der es eher um Darstellung und Testen geht. Die Fragen sind: (1) Was wähle ich als Zustand und (2) welches Verhalten soll wie belohnt werden?
Zu (1): Am Anfang wollte ich den Zustand so einfach wie möglich halten. Die Position besteht einfach aus der x- und y-Koordinate des Autos und dem Drehwinkel. Das hat auch Nachteile, dazu später mehr in einem Ausblick.
Zu (2): Die Belohnung ist schwieriger. Ich habe dazu die befahrbare Strecke in farblich markierte Abschnitte unterteilt. Die könnte man vor dem menschlichen Auge verbergen, aber ich lasse sie mal sichtbar. Ein Gewinn ist es für die KI immer, einen neuen, helleren Abschnitt aus einem dunkleren heraus zu erreichen; eine Niederlage, zu einem dunkleren zu wechseln. (Sonderregeln fürs Rundenende, weil da die Farben ja wieder von vorne losgehen.) Ins Grün zu geraten bringt auch Punktabzug. Sich im selben Abschnitt zu bewegen wird für den Anfang weder belohnt noch bestraft, es geht also nicht um Geschwindigkeit.
Dann funktioniert das schon ganz gut. Die erste Runde dauert sehr lange, weil am Anfang auch alle möglichen Varianten ausprobiert werden. Es gab 269 Respawns:
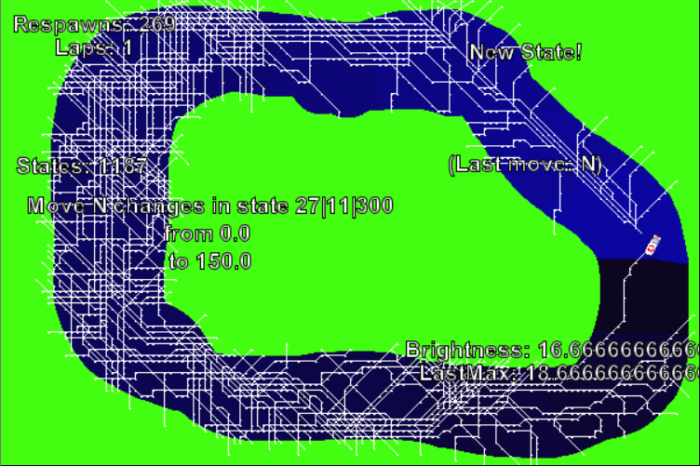
Nach der ersten erfolgreichen Runde geht es sehr viel schneller, und nach einigen solchen Runden ist die KI trainiert. Die folgende Strecke ändert sich dann auch nicht mehr und wird bei jeder Runde wiederholt:
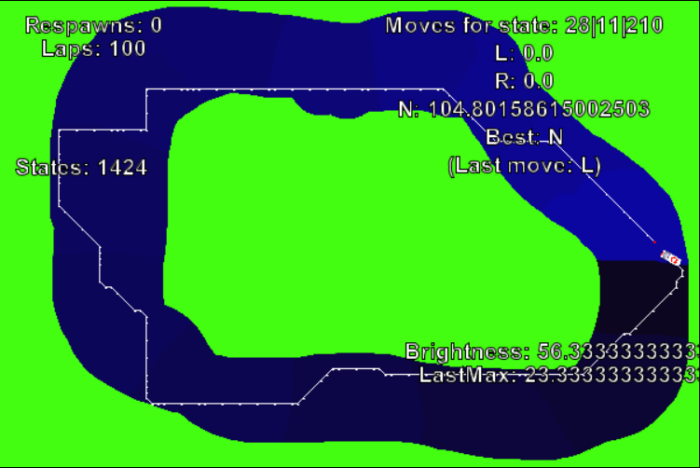
Die Explorationsrate im Einsatz
Dass die einmal für optimal befundene Strecke immer wiederholt wird, ist vielleicht gar nicht so sinnvoll. Manchmal landet das System nämlich in einer Sackgasse und wiederholt immer die gleiche Strecke, auch wenn sie nicht ins Ziel, sondern stets ins gleiche Grün führt. Ob das ein Bug ist oder unvermeidbar, das weiß ich nicht. Aber wenn man die Explorationsrate auch nur auf 0,01 setzt, gibt es bei jeder Entscheidung eine 1%-Chance, nicht automatisch die beste Entscheidung zu treffen. (Zugegeben, mit 1/3 nimmt man die dann zur Zeit immer noch.) Damit kommt man aus eventuellen Sackgassen und findet auch sonst interessante Alternativen. Und wenn die KI fertig trainiert ist, kann man die Explorationsrate wieder auf 0 setzen.
Das Bisherige als Video
Andere Strecken
Das alles funktioniert auch mit einer anderen Strecke:

Wenn man die Position des Autos und dessen Drehwinkel als Zustand nimmt, kommt man rasch zu einer Lösung. Allerdings lässt die sich nicht von einer Strecke zur anderen übertragen: Jede Strecke wird für sich gelernt, und mit unbekannten Strecken fängt man immer wieder ganz von vorne an. Das ist für die Praxis nicht sinnvoll. Also probieren wir etwas anderes.
Eine andere Zustandsberechnung
Ich habe das Auto mit einer variablen Anzahl von Sensoren ausgerüstet, die die Entfernung zum Grün messen, jeweils nach vorne und links und rechts oder hinten und so weiter. Der Zustand des Autos ist jetzt nicht mehr von der absoluten Position abhängig, sondern von der relativen Distanz zum Straßenrand.
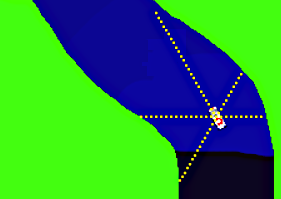
Bei 3 Sensoren und einer Reichweite von 25 sind das noch verkraftbare 15625 potentielle Zustände, bei 5 Sensoren knapp 10 Millionen. Praktisch komme ich bei der blauen Strecke aber nur auf 55000, auf der roten auf 200000. Und das funktioniert dann auch tatsächlich einigermaßen; hier als animiertes gif:

Zur Wiederholung noch einmal ein Überblick darüber, wie das funktioniert:
- Den aktuellen Zustand ermitteln und in der Q-Tabelle nachschauen, welcher Zug für diesen Zustand am besten bewertet ist, und diesen ausführen (oder eben explorativ einen zufälligen). Zum Beispiel Zustand 10:12:15:3:7: -> Zug 1
- Das Spiel ist jetzt in einem wahrscheinlich anderen Zustand, für den es vielleicht eine Belohnung gibt. Zum Beispiel neuer Zustand 8:11:15:8:12:, neue Zone erreicht, +10 Belohnung. Oder halt auch keine.
- So oder so diese Belohnung verrechnen: plus den (diskontierten) Wert des bestmöglichen Zugs im neuen Zustand und minus den Wert des alten Zugs (der Zug war ja 1) im vorherigen Zustand (der war ja 10:12:15:3:7:). Der Wert hat uns vorher noch nicht interessiert, nur dass es der beste Zug war.
- Das Ergebnis mit der Lernrate modifizieren, zum Beispiel * 0,75
- Den Wert des gemachten Zugs (immer noch 1) im alten Zustand (immer noch 10:12:15:3:7:) um das Ergebnis erhöhen.
- Von vorne anfangen, jetzt halt im Zustand 8:11:15:8:12:
Man bewertet also in Zustand A immer die Wahl des Zuges in Zustand B, der einen in diesen Zustand A gebracht hat, und zwar abhängig von den Möglichkeiten in B.
Das Lernen brauchte deutlich länger als mit dem naiven System, aber dennoch: dass das so einfach funktioniert, wunderte mich ein bisschen. Ich hatte doch vorher schon geglaubt, ein grundsätzliches Problem ausgemacht zu haben:
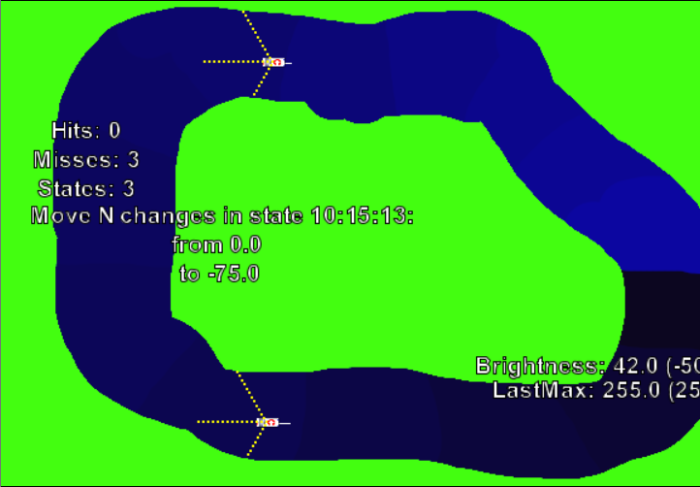
Beide Autos sind im gleichen Zustand: 10 Schritte links vom Straßenrand, 15 Schritte nach vorne sind frei, 13 Schritte nach links. Dennoch wird das obere Auto oben bei Geradeausfahren belohnt, weil es in die richtige Richtung fährt, und das untere Auto wird bestraft, weil es in die falsche Richtung fährt. Wie kann da sinnvolles Verhalten entstehen? Anscheinend taucht die Situation nicht oft auf.
Die Nagelprobe
Man kann die KI mit den Sensor-Autos natürlich auch auf Kurs 2 trainieren:

Kann nun eine KI, die auf dem komplexeren Kurs 2 erfolgreich trainiert wurde, auch auf dem fremden Kurs 1 einigermaßen bestehen, ohne neu dafür trainiert werden zu müssen? Sind die Erkenntnisse übertragbar? Wenn sich genug Zustände wiederholen und auch tatsächlich die gleichen erfolgreichen Züge bedeuten, dann hat die KI zumindest schon ein bisschen brauchbares Wissen.
Aktueller Stand: Nein, funktioniert nicht wirklich. Hilft es etwas, Anzahl und Reichweite der Sensoren zu verringern? Oder brauche ich eine andere Idee, wie ich Fortschritt im Kurs markieren könnte; schließlich sind die Farbzonen unterschiedlich. Ich kann natürlich zuerst den einen, dann den anderen Kurs trainieren; dann kann dieselbe KI beide Kurse fahren. Aber das ändert ja nichts am eigentlichen Problem.
Das grundsätzliche Problem
Die KI kann lernen, in einer bestimmten Situation (etwa: vorne 15 Platz, links 10, rechts 4) ein bestimmtes Verhalten zu zeigen. Und wenn danach die exakt gleiche Situation noch einmal eintritt, und sei es in einem anderen Teil der Strecke, wird sie dieses Verhalten wieder zeigen. Gut! Wir möchten aber eigentlich, dass das nicht nur bei einer exakt gleichen Situation geschieht, sondern bereits bei einer ähnlichen. Man will ja, dass die KI jede Linkskurve meistert und nicht nur eine Sammlung ganz konkreter geübter Linkskurven. Aber „ähnlich“ kennt unsere Q-Tabelle nicht, da wird jeder Zustand für sich betrachtet. Das Konzept „ähnlich“ kann allerdings ein Neuronales Netz entdecken. Und das wäre der nächste Schritt… dann könnte der Input auch wesentlich mehr Information enthalten, etwa auch andere Autos, denen man ausweichen müsste. Vielleicht komme ich noch dazu, aber fürs Erste ist die kleine Serie hier beendet.
(Und ja, wenn ich mich richtig auskennte, würde ich die passenden Werkzeuge nutzen, etwa alles gleich in Unity machen. So programmiere ich von Grund auf mit BlueJ und Greenfoot, den Schul-Entwicklungsumgebungen. Hilft aber auch beim Lernen.)
Links:
- https://www.youtube.com/watch?v=Tnu4O_xEmVk
Eine KI hat gelernt, MarioKart zu fahren, mit einem Neuronalen Netz - https://towardsdatascience.com/deep-q-learning-tutorial-mindqn-2a4c855abffc
Ein Q-Learning-Tutorial.
Nachtrag: Natürlich habe ich doch die Finger nicht vom Neuronalen Netz lassen können. Das war eine Fummelarbeit! Die richtige Kombination von Aktivierungsfunktion, Startbelegung, Lernrate und Bewertung zu finden war etwas mühsam. Aber dann funktioniert das, nicht immer so gut wie in dem Video unten, aber doch halbwegs. Trainiert wurde auf dem roten Kurs, aber das Auto schafft dann auch den blauen! Der Trick war, das Auto doch als Unterklasse zu SmoothMover zu machen statt als Actor, das ist so eine Greenfoot-Sache, wie genau die Koordinaten berechnet und gerundet werden. Viel muss das Netz nicht können, denke ich: „Wenn der Mittelsensor mindestens n lang ist, fahr geradeaus, außer wenn…“ und so.
Dabei reichen 3 Sensoren am Auto und ein Netz mit 5 Knoten im Hidden Layer. (Zuverlässiger aber mit ein paar mehr.) Das müssten noch wenig genug sein, um sich die Knoten zeigen zu lassen und herauszufinden, was welcher entscheidet.
Schreibe einen Kommentar