Autor: Herr Rau
-
Tests in der ByCS-Lernplattform
Abstract Zuerst geht es kurz darum, warum ich in der ByCS Lernplattform (Moodle) von H5P auf die hässlichere Moodle-Aktivität Test umgestiegen bin: das liegt an den Fragensammlungen. Dann zeige ich, wie man relativ einfach aus einer schlichten Textdatei mit vorbereiteten Fragen automatisch viele Moodle-Testfragen erstellen kann – denn die Fragen einzeln innerhalb von Moodle anzulegen…
-
Gelesenes und Gehörtes (Schnitzler, Eichendorff)
(4 Kommentare.) Arthur Schnitzler, Traumnovelle (Hörbuch.) Das kennt man durch die Kubrick-Verfilmung Eyes Wide Shut. Der Traum im Titel bezieht sich einmal auf einen fantasyhaften erotischen Traum Albertines, in dem sie ihrem Mann Fridolin untreu ist, und auf anderthalb traum-hafte Nächte, die Fridolin erlebt. Dabei schleicht er sich auf die Veranstaltung einer Geheimgesellschaft, die Bälle…
-
There Is No Antimemetics Division (mit Spoilern)
(5 Kommentare.) Ein Freund empfahl mir dieses Buch, Wir haben keine Antimemetikabteilung (Originaltitel: There is No Antimemetics Division) von Sam Hughes, ursprünglich erschienen unter dem Pseudonym qntm. Ist das Buch gut, nicht gut? Hat es mir gefallen? Das sind immer so schwierige Fragen. Vermutlich: Ja, es war gut, wenn auch nicht immer, und es hat…
-

Dann also doch: Das quritanische Pferd
(3 Kommentare.) Vor neun Jahren erreichte mich ein an mich adressierter Brief mit einem kleinen gehefteten Produkt darin: 8 Seiten, DIN A 6, sauber geheftet, also ein klassisches Zine-Format, wie man es beidseitig auf eine A4-Seite ausdruckt, diese faltet, zusammenheftet und an den Rändern einschneidet. (Armin Hanisch hat eine Vorlage, wie man das technisch am…
-
KW 12 – Yoga, Genitiv-Prädikativ, Ausschreibungen und KI-Texte (pfui)
(5 Kommentare.) Gestern das Vorbereiten abgebrochen und stattdessen Yoga gemacht: Ich will mich ein wenig mehr um mich selber kümmern, und dazu gehören Yoga und Laufen; beides hatte ich weitgehend eingestellt, um Zeit für anderes zu haben. Außerdem möchte ich zum Friseur. Ist das diese Midlife-Crisis, von der man früher so viel hörte? Ein Freund…
-
E.T.A. Hoffmann, Die Elixiere des Teufels
(4 Kommentare.) Ich höre nicht oft Hörbücher, als mir diese Fassung des Hoffmann-Romans unterkam (SWR Mediathek, sie nennen es Podcast, aber es ist natürlich keiner), griff ich aber zu. Via Buddenbohm, vielleicht? Ich kannte zuvor nur den Anfang des Romans, es stellte sich heraus: a) der Roman ist lang und verwirrend, und b) geht auf…
-
Perry Rhodan 150 bis 179
(1 Kommentare.) Wenn nichts geht: Perry Rhodan lesen geht. In den letzten Monaten habe ich weitere 30 Hefte gelesen. Neuanfang 150 (Scheer): Geht. Zeit ist vergangen; Rhodan ist jetzt Großadministrator der vereinten irdischen und arkonidischen Reiche, Atlan leitet die USO. Das ist eine vielversprechende Ausgangsposition für zukünftige Geschichten. Und mit den neuen Serienhelden in Form…
-
Aussprache-Spiele und -Videos
(9 Kommentare.) Frau Rau schickte mir einen Link zu einem Aussprache-Spiel: Man kann dabei verschiedene Spiele wählen, hier geht es um die unterschiedliche Aussprache von ä, e und i, die man mit dem Mikrofon richtig treffen muss. Ich versage kläglich bei diesem Spiel. Dabei bin ich solche Spiele fast gewöhnt, jedenfalls versage ich auf andere…
-
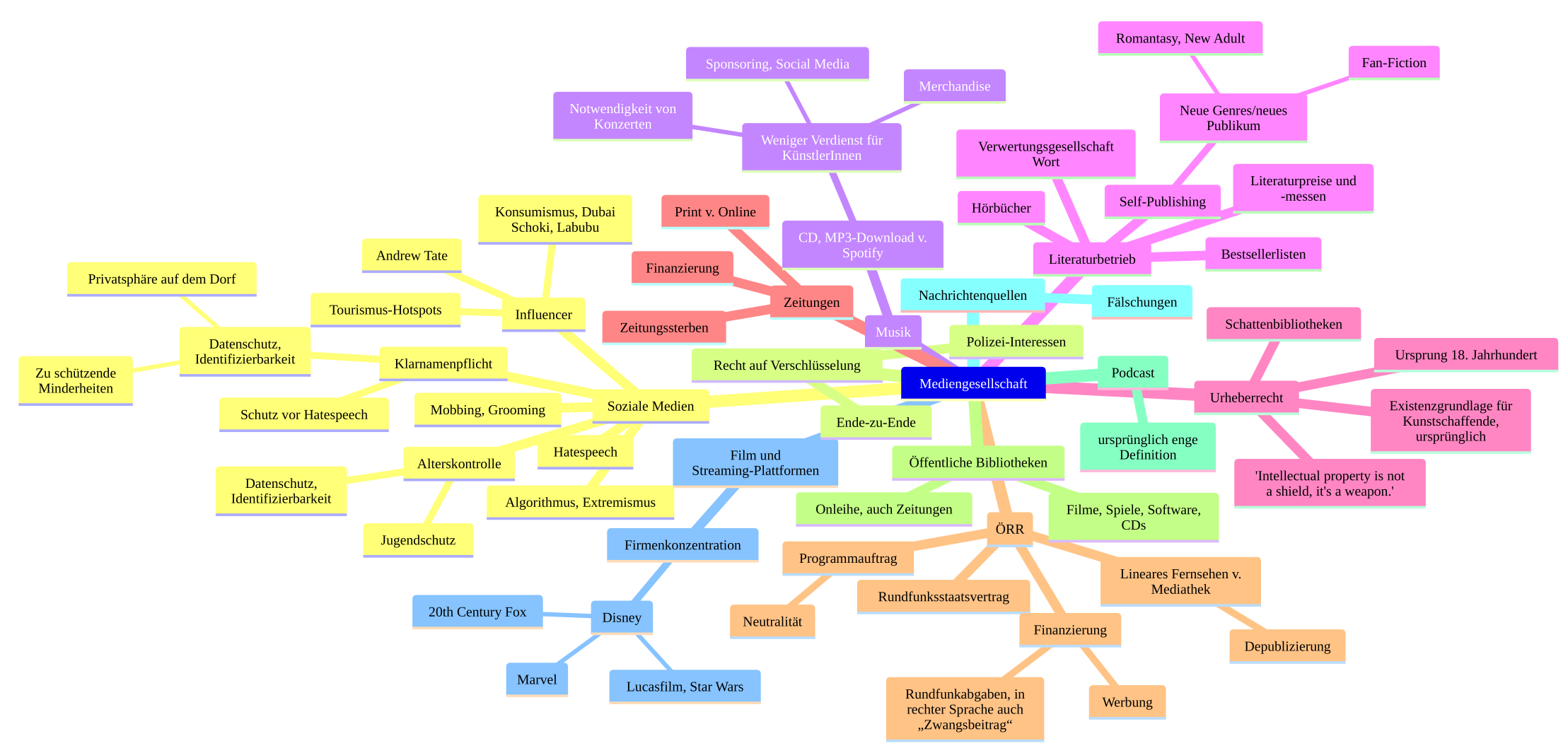
Unsere Mediengesellschaft im Deutschunterricht
(3 Kommentare.) (Ich soll mehr zu Deutsch machen und weniger zu Informatik, hat man mir gesagt. Nun gut!) Das Semester 13/2 ist extrem kurz. Das liegt auch daran, dass es 9 verschiedene schriftliche Abiturtermine gibt; im G8 waren es vier oder so. Und man muss mindestens 3 verschiedene Themen unterbringen, damit man die entsprechenden Schwerpunkte…
-
Eine Woche mit vielen Terminen
Montag: Gesamtkonferenz. Dienstag: Fachleitungstagung Informatik. Bis 17 Uhr! Den ersten Kaffee erst nach zwölf!!! Mittwoch: Personalversammlung. Freizeitlich: Münchner Kammerspiele, Play Auerbach! von Avishai Milstein. (War sehr gut.) Donnerstag: Teamtreffen an der Schule, Videokonferenz mit ISB-Arbeitskreis, abends freizeitlich auswärts. (Dort jungen Mann getroffen, dem ich in der Sportwoche der 7. Klassen das Konzept Pen-and-Paper-Rollenspiele erklärt habe,…
-

Fairphone-4-Erfahrungen nach drei Jahren
(7 Kommentare.) Mein Smartphone 4 Vor drei Jahren habe ich mir ein neues Smartphone gekauft, ein gebrauchtes Fairphone 4. Die Marke bemüht sich wenigstens um Nachhaltigkeit und Fairness. Bei den Geräten spüre ich als Verbraucher das am Ende daran, dass ich sie ganz leicht auseinandernehmen und reparieren kann, weil alle Elemente modular sind – die…
-

Mein neuer Mantel
(11 Kommentare.) In Wien wies mich Frau Rau beim Flanieren auf einen Mantel in einem Herrenmodengeschäft hin, einen Raglan-Mantel. Der würde mir stehen, meinte Frau Rau; ich pflichtete bei, betrat den Laden, worauf der Inhaber und ich bald handelseinig wurden. Raglan-Ärmel kannte Frau bereits, wusste aber nicht, dass die auf den Raglan-Mantel zurückgehen. Der ist…