Mit dem Open-Source-Programm Orange kann man große Datenmengen analysieren und visualisieren, also grafisch darstellen. Diese Daten kann man außerdem als Grundlage für maschinelles Lernen verwenden, das heißt, man trainiert einen Algorithmus (etwa ein neuronales Netz oder einen Entscheidungsbaum) mit einem Teil dieser Daten, um so Voraussagen für unbekannte zukünftige Daten zu ermöglichen. Wenn man etwa eine große Menge an Fotos von Katzen und Hunden hat, kann das System so lernen, auch neue Abbildungen dieser Tiere richtig zuzuordnen.
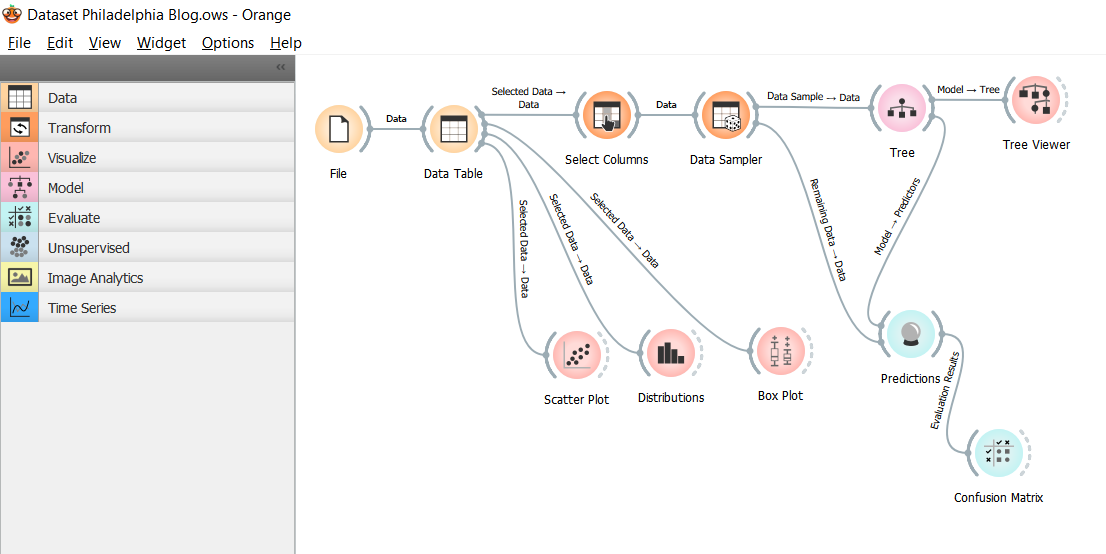
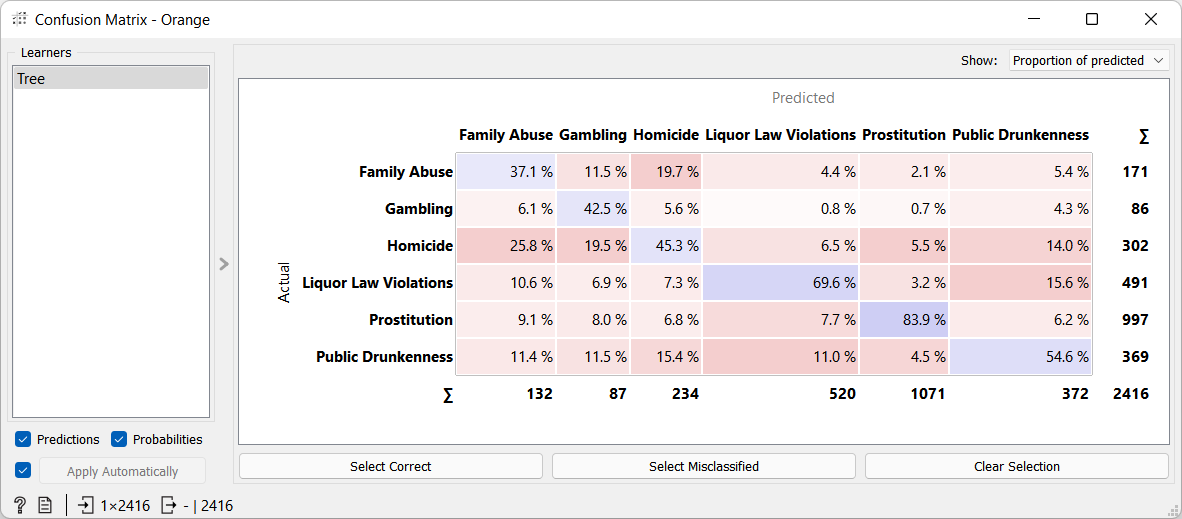
Im Beispiel unten aus der 9. Jahrgangsstufe werden Daten aus der (öffentlich zugänglichen) Verbrechensstatistik der amerikanischen Stadt Philadelphia mit Orange bearbeitet. Gespeichert sind dabei Art des Verbrechens, Uhrzeit, Datum, Längen- und Breitengrad. Der Arbeitsablauf in Orange lässt sich leicht aus den mitgelieferten Modulen zusammenklicken. In einem Säulendiagramm kann man sich die Verteilung der Uhrzeiten anschauen und erkennt Schwerpunkte (in der Nacht, aber auch ein wenig zur Mittagszeit). In einem Punktdiagramm kann man sich zum Beispiel Längen- und Breitengrad und Art des Verbrechens darstellen. So kann man den Umriss von Philadelphia gut erkennen und sieht auch hier eine Konzentration von bestimmten Verbrechensarten auf bestimmte Gebiete. Und zuletzt kann man überprüfen, wie sehr sich etwa aus Uhrzeit-, Längen- und Breitengrad vorhersagen lässt, um welche Art Verbrechen es sich handelt.
Hier im Film erklärt:
Für eine tatsächliche Voraussage ist die Datenmenge natürlich immer noch zu klein, es sind knapp 10000 Datensätze. Obendrein sind solche Voraussagen ethisch problematisch, schnell gibt es Vorurteile über ganze Viertel, und womöglich sich selbst bestätigende Vorurteile. Außerdem muss stets hinterfragt werden, wie korrekt oder sinnvoll solche Voraussagen sind, und welche Schlüsse man aus ihnen ziehen darf und welche nicht – oft erkennen Maschinen ebenso wie Menschen Muster, wo gar keine sind.


Beim Oldenbourg-Schulbuch gibt es auch ein bisschen Material, insbesondere eine Datei „3_2_A05a_Praktikum.zip“ – 2000 Datensätze mit vergangenen Kandidaten und Kandidatinnen für ein Praktikum. Gespeichert sind darin verschiedene Attribute, also Mathematik- und Deutschnote, Geschlecht, Brille oder nicht, Nationalität. Aus dieser Gruppe haben etwa 25% das Praktikum erhalten, der Rest nicht. Lässt sich ein Algorithmus erzeugen (etwa ein Entscheidungsbaum), der das automatisch nach bisherigem Muster vornimmt, um damit in Zukunft die Entscheidung für ein Praktikum automatisiert zu fällen?
Mitgeliefert mit Orange werden viele weitere Datensammlungen, etwa Überlebende der Titanic, mit Daten zu Passagierklasse, Geschlecht, Alter. Lässt sich da ein Muster erkennen?
Dazu noch: Leberwerte, „Fluorescence images of the nucleus of mouse fully-grown antral oocytes from University of Pavia“, illegale Müllhalden oder Verkehrsunfälle in Slowenien, Abstimmungsverhalten, Zeichnungen von Verkehrszeichen oder römischen Amphoren.
Denn auch Fotos kann man mit Orange analysieren und kategorisieren, bei meiner Sammlung von Balkonvögeln kann es Amseln und Meisen gut unterscheiden. (Oder unterscheidet er nur die Kameraposition, weil ich die Tiere jeweils auf andere Art aufnehme?)
Mit einem Zugang zur Twitter-API kann man Textanalyse von Tweets betreiben, oder eine kapitel- oder satzweise sentiment analysis von Erzählungen vornehmen – also, ob die Stimmung darin, grob gesagt, eher positiv oder eher negativ ist. Ich habe bislang aber nur ausprobiert, dass das technisch geht, ob sich interessante Ergebnisse finden lassen, weiß ich noch nicht. Orange ist ein tolles Werkzeug, und man wünscht sich immer mehr Datensätze. Zeugnisnoten und Geschlecht am Ende der 6. Jahrgangsstufe – lässt sich da schon die Abiturnote vorhersagen? Das ist natürlich verboten, und diese Daten habe ich auch nicht, aber spannend wäre es schon. Die Versuchung wäre da.
Anhänge:
Schreibe einen Kommentar