Für 60 Euro kann man sich einen Packen Perry-Rhodan-Hefte kaufen, etwa Heft 50 bis 99, das sind 3000 Heftseiten mit 1,4 Millionen Wörtern, im EPUB-Format, ohne Kopier- und Arbeitsschutz. Also arbeite ich damit auch!
Schritt 1: Wörter suchen
Und zwar habe ich die Hefte mit der Informatik-Suite Orange Data Mining analysiert, über die ich schon mehrfach geschrieben habe. Man bastelt sich damit einen Datenfluss so wie hier im Bild:
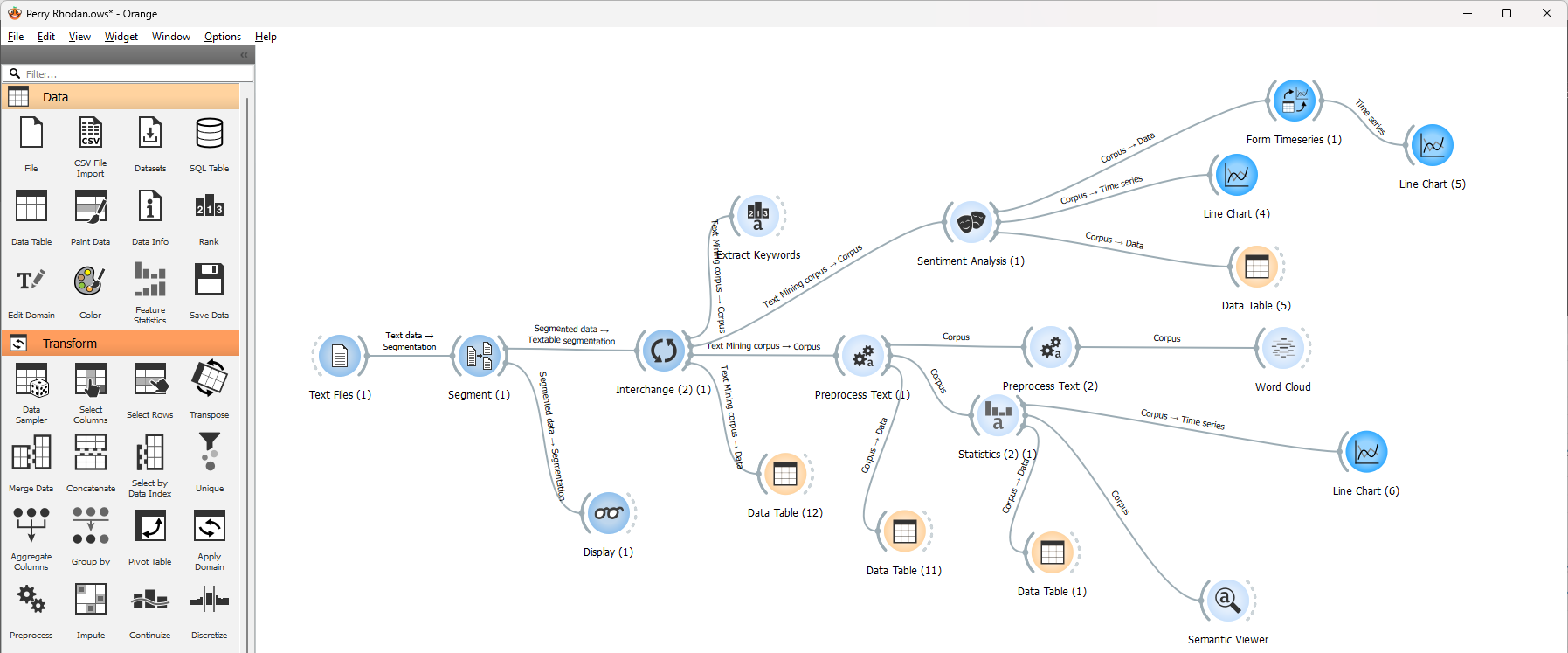
Links wird die – von mir nur wenig vorbereitete – Textdatei geladen, danach anhand der Titelnummerierung segmentiert, so dass 50 Einzeltexte daraus entstehen. Diese habe ich dann normalisiert, was Groß- und Kleinschreibung betrifft, danach nach bestimmen Wörtern durchsucht, und in einem letzten Schritt das Ergebnis dieser Durchsuchung visualisiert.
Das Diagramm weiter unten ist diese Visualisierung. Es zeigt an, wie oft bestimmte Wörter oder Wortbestandteile in den Heften 51 bis 99 auftauchen. Die x-Achse für alle Zeilen ist mit 0-49 nummeriert, das sind in diesem Fall die Hefte 50 bis 99, man müsste also immer 50 addieren, um die Heftnummer zu kriegen. (Es ist fast reiner Zufall, dass ich nicht mit dem ersten Packen, den Heften 1 bis 49, begonnen habe.)
- Die ersten drei Zeilen entsprechen den drei wichtigen Autoren K. H. Scheer, Clark Darlton und Kurt Mahr. Jeder Autorenname taucht in dieser Form exakt einmal pro Heft auf, das sind die Zackenspitzen der ersten drei Zeilen, alle natürlich gleich hoch. Bei einer ernsthafteren Auswertung würde man das anders machen, aber so kann ich das mit den anderen Zeilen schön zusammenbringen.

- Zeile 4 in der Mitte enthält den Prozentsatz an unique words, Wörtern, die nur einmal pro Heft auftauchen. Die Unterschiede sind in Prozent nicht sehr groß, zwischen 0,17% und 0,23% – aber man sieht doch, dass es deutliche Spitzen gibt, und die korrelieren ziemlich eindeutig mit einem der drei Autoren oben.
- Die fünfte Zeile untersucht, wie oft „sinnend“ auftaucht. Das ist mir nämlich mehrfach unangenehm aufgestoßen, stilistisch. Wir sehen zumindest: Kurt Mahr nutzt das Wort nicht, Clark Darlton gerne und K. H. Scheer auch.
- Die sechste Zeile untersucht das Vorkommen von „gucky“, denn „Gucky“ heißt eine Hauptperson, die besonders mit einem Autor assoziiert wird. Und das sieht man auch. Das heißt jetzt nicht, dass der Gucky besonders gerne verwendet, sondern eher, dass er die Hefte kriegt, in denen diese Figur eine besonders große Rolle spielt.
- Die letzte Zeile schaut sich an, wie oft der Name „Thora“ fällt, Perry Rhodans Frau, die im Verlauf der Serie stirbt. Man sieht: Sie taucht eigentlich nur in drei Heften auf und ist sonstwenig bis gar nicht erwähnt.
„Zigarette“ gibt es bei den meisten Heften von Kurt Mahr und bei vielen von Kurt Brand, auch bei 2 von 4 Heften William Voltz, nie bei Clark Darlton und nur einmal bei den 8 Heften K. H. Scheer. Die Spitzen bei „fremd“ sind bei Kurt Mahr.
Exkurs: Weitere Untersuchungen
Was ohne grammatische Analyse leider nicht geht: Genitivobjekte heraussuchen. Orange kann das nicht, andere Programme schon, ich weiß nicht, wie gut. Von dieser Art der Analyse ist man ja im Moment etwas abgekommen. Dennoch, ich hätte gerne eine Liste der vielen Genitivobjekte, die man in Unterhaltungsliteratur der frühen 1960er Jahren noch verwendete. Herausgeschrieben habe ich mir nur ein paar:
- erinnerte er sich der Ankündigung Talamons
- erinnerte er sich der Wachroboter
- erinnerte er sich der Warnung
- Chellish kroch hinunter, der Sonne nicht achtend
- Einen Planeten, den eine Invasion aus dem Raum jeden Lebens beraubt hatte
- um der Druuf-Gefahr Herr zu werden
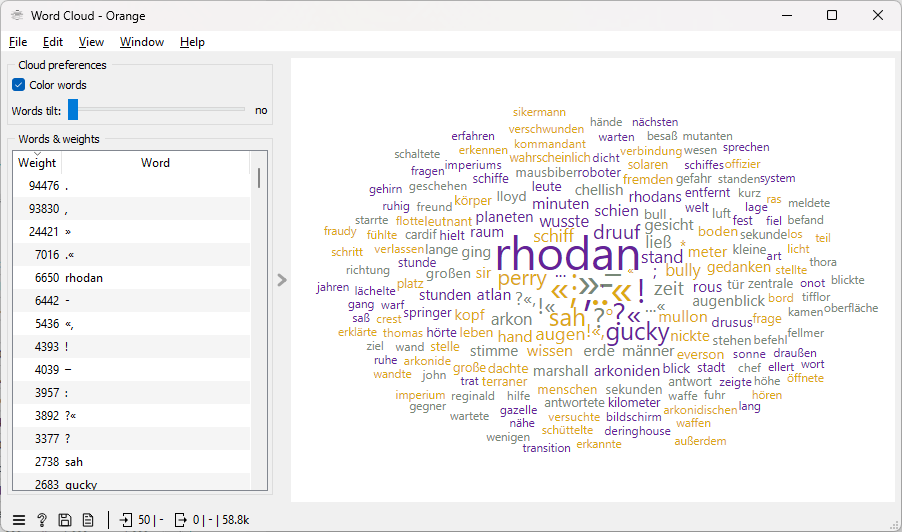
An der Wortwolke merkt man, wie zentral Rhodan ist. Allerdings taucht der Name auch immer wieder in redaktionellem Zusammenhang auf, und bei dieser Grafik habe ich diese Bereiche noch nicht herausgefiltert:
Schritt 2: Und jetzt noch einmal mit KI
Macht man jetzt nicht alles mit KI, höre ich rufen? Der erste Gedanke: Man füttert die KI mit den Texten, und lässt die KI auf unmittelbarer Basis der Texte zum Beispiel analysieren, welche Text wahrscheinlich vom gleichen Autor geschrieben wurde. Die Autoren gibt man dabei vor. Zu diesem Zweck habe ich die Ursprungsdatei noch weiter geändert, so dass ich Nummer, Autor, redaktionelle Beiträge und Inhalt separat betrachten kann.
Man kann sich das wie bei Bilddateien vorstellen. Da kann man die Bilder als auszuwertende Datensätze wirklich Pixel für Pixel eingeben und die KI mit diesen Datensätzen so trainieren, dass sie Hunde und Katzen unterscheidet oder Verkehrsschilder und Buchstaben erkennt. Ein Bild selbst mit nur 100 mal 100 Pixeln Auflösung hat 10000 Pixel, die man bearbeitet. Das geht schon noch, ist aber auch schon recht viel. Und erst bei größeren Bildern… In der Praxis macht man das wohl anders, nämlich indem man eine Art Fingerabdruck des Bildes macht und dann mit diesem Fingerabdruck arbeitet. Der Fingerabdruck enthält dann nicht 10000 oder 1000000 Werte für die verschiedenen Pixel, sondern nur 2047 Werte für 2047 Dimensionen. Was die bedeuten, lässt sich schlecht sagen, das kommt vom Fingerabdruckmachsystem; sie bedeuten letztlich gar nichts für uns. Aber mit diesen Werten lässt sich leichter rechnen.
Man kann auch gut unbearbeitete Texte analysieren, etwa indem man nach bestimmten Wörtern sucht wie „Gucky“ oder „sinnend“ oder „Zigarette“. Die Auswahl, welche Wörter dabei ergiebig sind, die muss allerdings ein Mensch treffen. Man kann auch eine sentiment analysis machen, dabei wird auf Grundlage einer vorgegebenen Liste von solchen Wörtern untersucht, wie viel emotional positive oder negative Wörter enthalten sind. (Die Kategorien sind tatsächlich auch ein wenig differenzierter, wenn auch nicht so sehr, wie man das gerne hätte.)
Man kann aber auch ohne menschliches Mitdenken in Form solcher Listen versuchen, die Texte zu analysieren, um sie etwa zu kategorisieren und Autoren zuzuordnen. Dabei wird auch wieder ein Fingerabdruck der Textdatei erzeugt, wiederum nach einem Fingerabdruckmachsystem, und am Ende wird der Text auf, sagen wir, 384 Dimensionen reduziert. Man wünscht sich dann, dass verschiedene Texte, die in diesem 384-dimensionalem Raum benachbart sind, auch wirklich etwas miteinander zu tun haben. (Siehe längeren, aber auch nicht einfacheren Blogeintrag.)
KI mit menschlicher Vorarbeit
Ich gebe der KI vor, welche Kategorien sie anschauen soll, also die Häufigkeit von „Gucky“ und „sinnend“ und unique words. Und mit diesen Dimensionen arbeitet die KI, und eben nicht unmittelbar auf dem Text.
Wenn ich nur mit „contains“ und den Wörtern „atlan, perry, gucky, sinnend, fremd, thora, orgel, zigarette“ arbeite, hat der automatisch erstellte Entscheidungsbaum sieben Entscheidungsebenen. Dabei spielen „perry“ und „gucky“ eine große Rolle, „sinnend“ wird gar nicht verwendet:
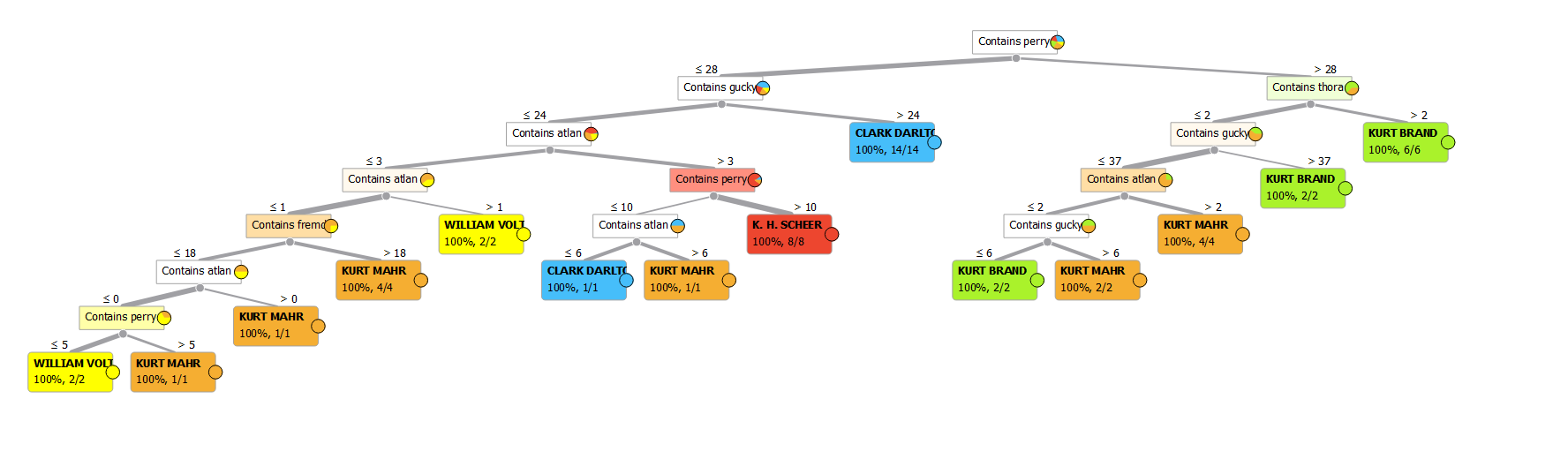
Stelle ich zusätzlich %unique words zur Verfügung, sind es nur noch sechs Ebenen:
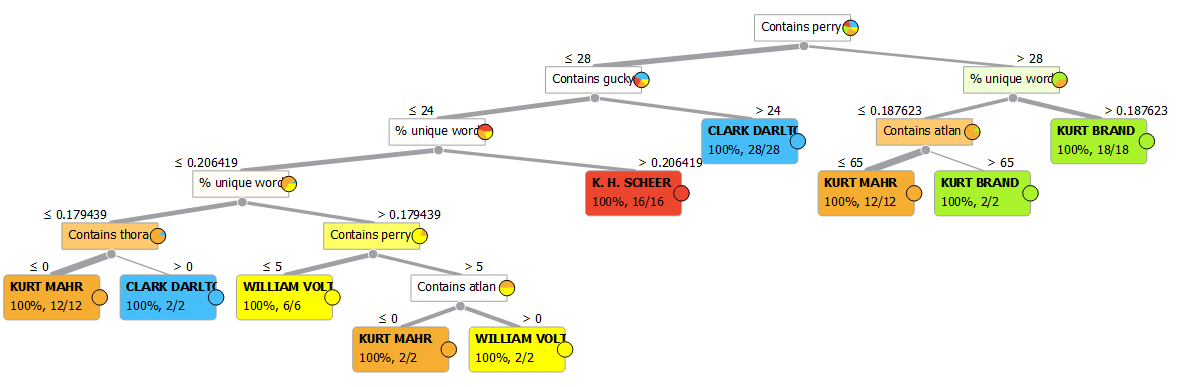
(Hinweis: Der automatisch erstellte Baum ist nicht zwangsläufig optimal.)
KI ohne menschliche Vorarbeit (also: von jemand anderem geleisteter)
In diesem Fall wähle ich die Dimensionen nicht selbst aus, sondern lasse nach dem Fingerabdruckmachsystem die 384 Standard-Dimensionen erstellen und die KI damit arbeiten. Es stellt sich heraus, dass es nur maximal fünf Entscheidungsfragen braucht, bis alle Autoren zugeordnet sind:
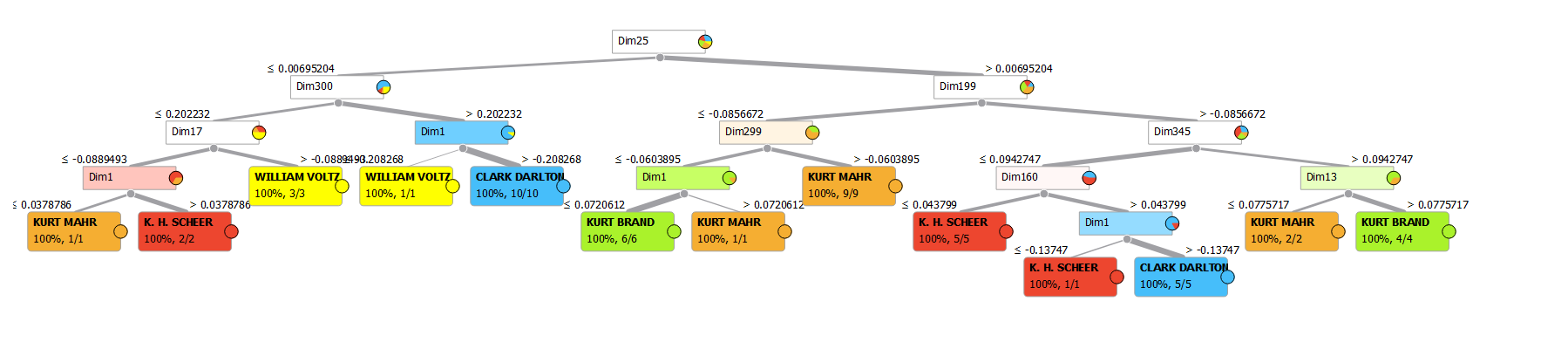
Am relevantesten ist ist dabei die Dimension 25, danach Dimension 199. Wer hätte das gedacht! Freiwillige Zusatzaufgabe: Wer findet manuell Suchbegriffe, so dass nur vier Entscheidungsfragen für die eindeutige Zuordnung nötig sind, also besser als das embedding in 384 Dimensionen? Gibt es das? Wäre das wirklich nur für die 50 Hefte verwendbar und würde bei 50 weiteren Heften versagen? Vermutlich kann man sich ein Skript schreiben, dass Wort für Wort alles durchprobiert.
Ein grundsätzliches Problem
Ich habe bei den Berechnungen oben übrigens einen Kardinalfehler begangen. Ich habe in beiden Fällen die Systeme mit 50 Heften gefüttert und 50 Hefte zuordnen lassen und mir auf die Schulter geklopft, dass die KI das kann.
Aber ohne eine weitere Überprüfung heißt das gar nichts. Was ich vielmehr tun müsste: mit etwa 80% meiner Datensätze die KI trainieren, also den Entscheidungsbaum erstellen lassen, um dann mit denn 20% verbliebenen Datensätzen zu testen, ob die KI mit neuen, unbekannte Datensätze korrekt zuordnen, bei der sie die Lösung nicht schon vorher weiß. Da erlebt man oft böse Überraschungen.
Allerdings sind 50 Datensätze einfach zu wenig, um damit gut zu arbeiten, zumal ein Autor nur 4 Hefte geschrieben hat. So wie der verrückte Wissenschaftler die Hände zum Himmel reckt und nach mehr, mehr!, MEHR!! Elektrizität verlangt, wünscht sich der KI-Bastler mehr, mehr!, MEHR!! Daten. Aber die habe ich nicht; ob es etwas bringen würde, die Hefte nicht im Ganzen, sondern nach Kapiteln zu untersuchen? Dann hätte ich vielleicht die zehnfache Menge an Datensätzen.
Schritt 3: Bringt uns das alles etwas?
Vielleicht nicht. Es ist ein Spielzeug, und schlimmstenfalls eine Text-Physiognomik, eine Pseudowissenschaft, bei der man misst, was sich messen lässt, und daraus DInge abzuleiten können glaubt. Eventuell interessant könnte die sentiment analysis sein, aber meine Erfahrungen damit sind bisher eher so mäßig.
Schritt 4: Muss ich jetzt ins Gefängnis?
Nein, das ist alles legal. Weil ja kein Kopier- und Arbeitsschutz auf der gekauften Datei liegt. Sonst wäre wohl der Hackerparagaph auf mich anzuwenden, weil ich mir Zugang zu Daten verschafft habe, die nicht für mich gedacht sind, und dabei auch noch Hackerwerkzeuge verwendet habe. Texteditoren und so. Puh, noch einmal Glück gehabt.
(Das war es jetzt erst einmal mit Perry Rhodan, denke ich. Bald wieder Schul-Content.)
Schreibe einen Kommentar