Monat: September 2011
-

Ich mach jetzt auch mal was mit diesem Post-Privacy-Ding
(9 Kommentare.) Wer meint, Urlaubsdias seien privat und uninteressant und gehörten nicht ins öffentliche Netz, dem muss ich demonstrieren, dass es noch Privateres und Uninteressanteres gibt: mindestens das öffentliche Üben von Musikstücken. Also mache ich das jetzt mal. Der Hintergrund: ich spiele seit einem halben Jahr Ukulelespielen. Ein paar Griffe und musikalisches Grundwissen habe ich…
-
Mein Unterricht 2011 (Unterrichtminus sozusagen)
(11 Kommentare.) Dieses Schuljahr unterrichte ich nicht nur kein Englisch (im vierten Jahr, mehr oder weniger), sondern auch kein Deutsch – stattdessen nur Informatik. Das ist ungewohnt, auch weil ich, äh, kleiner Fachbetreuer für Deutsch bin. Kein Schulaufgabeneintrag, keine Schulaufgabenkorrekturen, nur Nebenfachlehrer sein. Ich unterrichte dieses Jahr aber auch nicht gar so viele Stunden, unter…
-
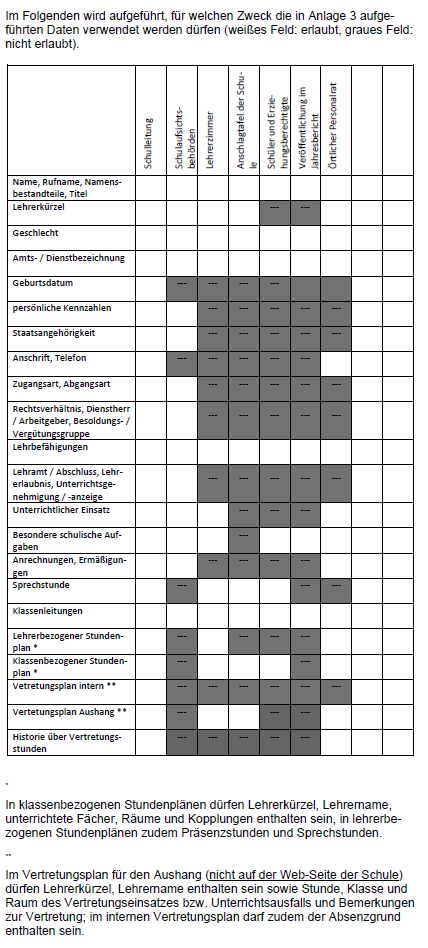
Das bayerische Schulverwaltungsprogramm ASV
(6 Kommentare.) Hear ye, hear ye! Zeichen erscheinen am Himmel. Ein solches Zeichen ist die Dienstvereinbarung über die Einführung und Anwendung des bayerischen Schulverwaltungsprogramms ASV (pdf), die man auf der Verkündungsplattform der Bayrischen Staatsregierung einsehen kann. (Ich sage das Wort „Verkündungsplattform“ zu gern.) ASV ist das von der Regierung den Schulen zu Verfügung gestellte Schulverwaltungsprogramm,…
-
Das Schuljahr beginnt, Projektsoftware, Datenschutzfragen
(8 Kommentare.) Das Schuljahr beginnt, wenn auch langsam. Ich muss erst einmal den Informatik-Kongress letzte Woche verdauen, von dem ich mir mehr Anregungen geholt habe, als ich je umsetzen werden kann (und die ich erst einmal sortieren muss). Aber das ist okay, man braucht ja viele Möglichkeiten, Dinge im Unterricht umzusetzen, damit man auswählen kann,…
-

Auf dem Weg zum Kongress.
(3 Kommentare.) Versuche, nach Informatiker auszusehen. (Münster, INFOS2011) Nachtrag: Denn ja, ich bin noch nicht in der Schule – war das nur letzte Woche, noch ohne Schüler, friedlich und aufgeräumt. Ich hätte schon ganz gerne eine Klausur-Woche in der Schule, in der sich Lehrer treffen und in Ruhe Dinge besprechen. Zum Beispiel Ende Juli: Bis…
-

Kleines Entzifferungsproblem
(12 Kommentare.) Im Auftrag der Ahnenforschung: Ich habe hier in sehr schlechter Qualität den Scan einer Registration Card eines Verwandten von 1917. Geboren in England, ausgewandert, eingebürgert. Ich soll beim Entziffern helfen. Das meiste ist klar: geboren am 28. eines Monats im Jahr 1887. Darunter Naturalized citizen. Frau und fünf Kinder. Aber dazwischen, über dem…
-
Verlängerung des Leistungsschutzrechts für Musikaufnahmen
Texter und Komponisten genießen das Urheberrecht an ihren Werken. (Genießen wird meistens der Rechteinhaber, also der, dem sie die Verwertungsrechte verkauft haben.) Das regelt die GEMA. Darüber hinaus sind Musikaufnahmen geschützt, also konkrete Einspielungen eines Werk auf einer Platte. Das regelt nicht die GEMA, soweit ich weiß. Diese Musikaufnahmen sind zur Zeit 50 Jahre lang…
-

ISO 8859-1, UTF-8 und Wordpress
(7 Kommentare.) (Theoretischen Teil überspringen und gleich zur Lösung der Aufgabe springen, die im Titel angekündigt wird. Aber das ist nur für technische Blogbastler interessant.) Inzwischen ist aus einem kurzen Eintrag ein langer geworden, und er erklärt nicht mehr das, was er am Anfang sollte. Ich sollte ihn wirklich kürzen und neu strukturieren. Der Unterschied…